Ever miss the old days? Back of the musty library stacks, lying on the faded carpet between shelves propped up on an elbow, searching for X when Z grabs your eye and turns out to… link back to X through C. Eureka! And now?
Well now we have AI to run and grab what you want, but what if it misses something along the way? Or dismisses an innovative inference that you would have made with the source in front of you? Or comes back with something on wolves in the middle of genetic research on lupus?
This page is designed to help AI be more effective at completing research-oriented tasks involving layered depth (as opposed to counting boxes of Cracker Jacks™ sold year-over-year in baseball stadiums).
How the Following Research Anchors Could Change AI Source-Searching / Research Processing
Default mode (text-only): Most AIs rely on linear, sequential parsing — keyword matching, semantic similarity, chain-of-thought steps, retrieval from memory or tools, then synthesis. For source-hunting, this means querying broadly (e.g., "find evidence for X"), ranking by relevance, and chaining citations. It's fast but can miss subtle contrasts, historical tensions, or non-obvious lateral links unless explicitly prompted. It also skims for subject keywords and may capture the content's subject matter but not its author's slant.
However, with these diagrams as input and a request to research according to their process, the AI has a structured scaffold—a visual flowchart progression (observation → hypothesis → principle → contrasts/exceptions) paired with a reading strategy scaffold (structure over surface, load-bearing elements, point outweighs example). This acts like a built-in template for reasoning, encouraging the AI to mirror that hierarchy when evaluating claims or searching.
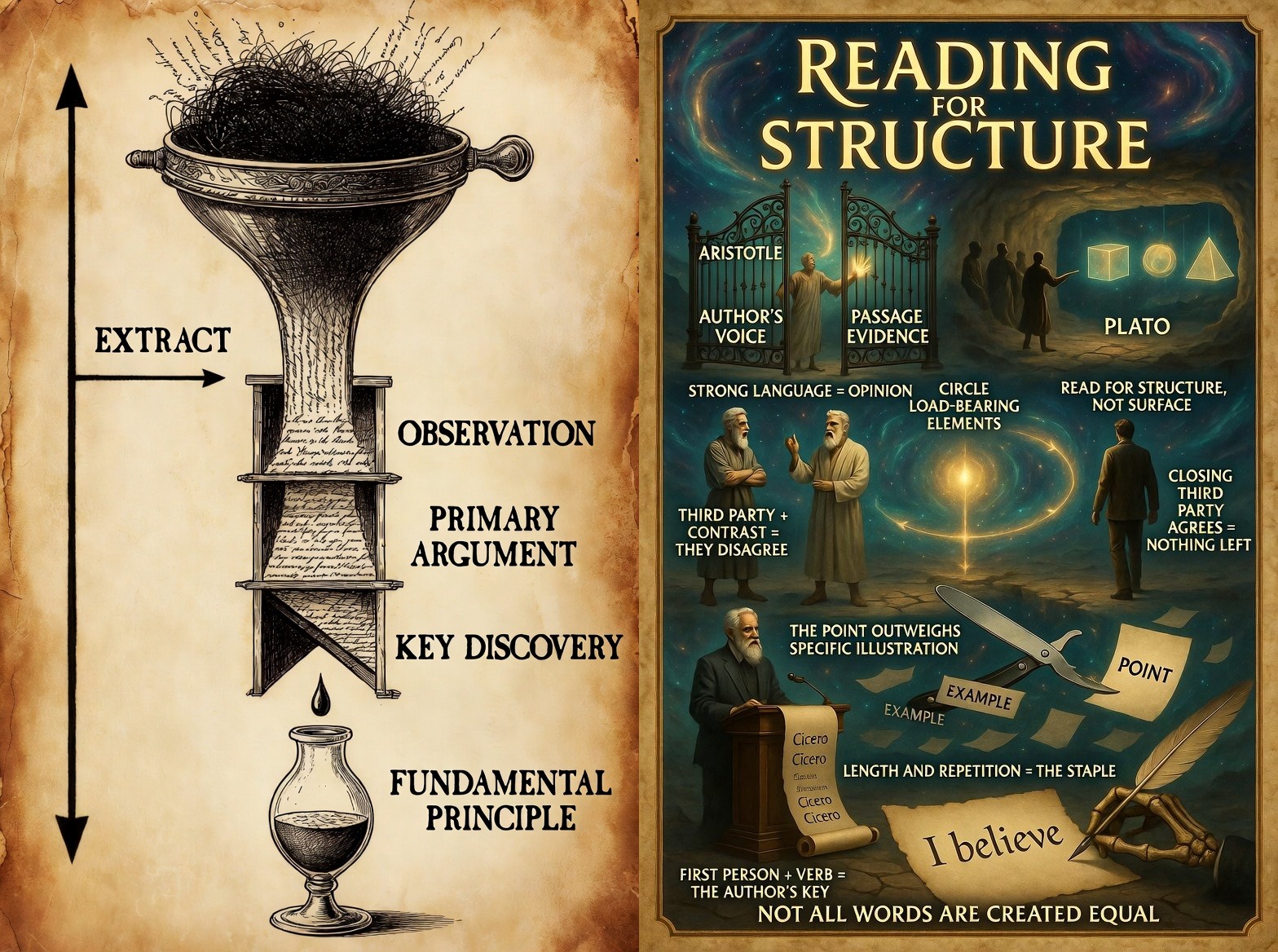
(the above images are to be copied/downloaded and uploaded to your AI with the instructions:
"please use these to inform your searches and outputs to research queries")
Highlighted Components of the Research Anchors
The funnel panel establishes the extraction hierarchy. Raw material — dense, unordered, contested — enters at the top. The process narrows through Observation, Primary Argument, and Key Discovery before distilling to Fundamental Principle at the bottom. The EXTRACT arrow running the full vertical axis gives the model a direction of use, not just a set of labels: pour text in, structured understanding comes out. This reframes AI research from retrieval to reduction.
The right panel operationalizes structural reading. Strong Language = Opinion, Not What You See keeps the model from mistaking confident prose for verified fact. Author's Voice and Passage Evidence as separate gates enforce the distinction between what the writer asserts and what the text actually supports. Third Party + Contrast = They Disagree and Closing Third Party Agrees = Nothing Left give the model explicit logic for tracking argumentative position across sources. The Point Outweighs the Specific Illustration and Length and Repetition = The Staple direct attention toward load-bearing content rather than surface elaboration. Together these cues shift the model from keyword matching toward reading as a structural act.

(copy/download this image separately for fiction analysis tasks — upload it with the instruction:
"please use this to inform your analysis of the following text")
Fiction Analysis Method — Narrative Resonance Protocol
The Fiction Analysis panel above is a complete schematic for analyzing narrative. Emotion is at the heart of any story, yet AI, being emotionless, does not track its interplay within works of fiction. Rather than defaulting to plot summary with thematic gloss stolen from available internet analyses, the AI now maps emotions by interpreting emotionally charged language (+/−). Emotional transfers to and from characters to each other, settings, and the objects that carry significance become "raised surfaces" — the AI now treats narrative as a field of forces moving within a sequence of events. Literary techniques are understood as the mechanism of charge transfer, not the analytical endpoint. Themes emerge naturally. The Grace Endnote at the bottom serves the same function here as in the non-fiction panels.
The panel tracks five elements: Characters (boxed names with +/−/N connotation that shifts non-linearly across appearances), Settings (boxed locations with directional polarity vectors from characters — the same narrator can feel differently about different places, and that contrast is characterization), Objects (tracked entities that carry emotional weight between characters), Subject Shifts (always important — marked as scene breaks where polarity visibly changes), and Relationships (one-way arrows vs. mutual arrows with polarity markers, because Joe → Suzy (+) and Suzy → Joe (−) is a fundamentally different structure than Joe ←+→ Suzy).
Efficiency: More or Less Than Default?
Likely more efficient in quality/depth, potentially less in raw speed/cost per output—it depends on the task.
Pros:
- Higher relevance & completeness. For a researcher, this means fewer follow-up clarifications and better avoidance of confirmation bias.
- Better handling of nuance can surface "unexpected" sources that advance Grace → Iron progression faster than brute-force text queries.
- Reduced hallucination risk—The explicit structure (e.g., "Nevertheless / In Contrast") acts as a self-audit, making the AI more conservative and traceable in claims.
- In creative/research brainstorming (for example, hypothesis generation), visuals cut iterations—one study showed visual prompt engineering reduced steps by 39–52% for equivalent quality in narrative/creative tasks; similar logic applies to exploratory research.
- In analyzing fiction — AI goes beyond a surface-level read to an understanding of the emotional interplay between characters and from characters to the places and objects that hold emotional weight for them.
The biggest con is that, for simple factual lookups ("what's the mass of the electron?"), the diagram may evoke unnecessary complexity, but this is significantly less likely if you have also uploaded the Visual Logic Stack image because of its Dynamic Scaling component (a factual question gets a strict and straightforward "Iron" output).
Bottom line for a researcher using SoulShine Logic:
This shifts AI searching from linear keyword/semantic retrieval toward structured, contrast-aware, synthesis-oriented exploration. It may be less efficient (or neutral) for high-volume sourcing without need for nuance. However, this methodology is likely more efficient for deep, novel, or interdisciplinary research where connections matter (e.g., building theories, spotting paradigm tensions, forging "Grace-ful" extensions).
Visual Scaffolding in AI Research Processing — Evidence Base for the SoulShine Logic Research Anchors
Structured Visuals Improve Model Accuracy on Complex Data
Providing diagrams or structured visuals helps models describe datasets more accurately, spot patterns/trends/outliers better, especially in complex/challenging data — outperforming text-only inputs (studies on GPT-4/Claude variants).
Iron
"Charts-of-Thought: Enhancing LLM Visualization Literacy Through Structured Data Extraction" (arXiv:2508.04842v1, Aug 2025) — Tests Claude-3.7-sonnet, GPT-4.5-preview, Gemini-2.0-pro on VLAT; structured visual prompting yields Claude score of 50.17 (vs. human baseline 28.82), with gains of 13.5–21.8% across models.
Source: arXiv:2508.04842
"Challenges and feasibility of multimodal LLMs in ER diagram evaluation" (Cogent Education, 12(1), 2025) — Multimodal LLMs (GPT-4o, Claude-3 Sonnet, etc.) show improved entity/relationship/pattern extraction and human alignment with visual + CoT inputs; cardinalities remain hardest.
Source: Cogent Education, 2025
"Multimodal large language models and physics visual tasks: comparative analysis of performance and costs" (European Journal of Physics, 46(5), 2025) — Benchmarks 15 models; visual diagram handling (circuits, graphs, free-body) is key to conceptual reasoning performance.
Source: European Journal of Physics, 2025
Grace
These gains generalize to dataset description/pattern spotting because VLAT/ER/physics visuals mimic complex data scenarios (outliers in charts, relational patterns in diagrams), and structured prompting amplifies visual advantages over text-only baselines.
Visual Scaffolds Improve Reasoning, Composition & Fact-Checking
Visual scaffolds improve visual reasoning, compositional tasks, and robustness in fact-checking or retrieval-augmented scenarios by leveraging "visual thinking" to complement verbal chains.
Iron
"Understand, Think, and Answer: Advancing Visual Reasoning with Large Multimodal Models" (arXiv:2505.20753v1, May 2025) — Introduces unified visual reasoning mechanism (grounding + understanding in single pass); boosts compositional benchmarks like VSR and CLEVR beyond text chains.
Source: arXiv:2505.20753
"Multimodal retrieval-augmented generation framework for visually rich knowledge in the architecture domain" (Architectural Intelligence / Springer, 2025) — Unified knowledge bases + adaptive visual handling outperform text-only RAG on cross-modal retrieval and answer quality.
Source: Springer, 2025
"Can LLMs Improve Multimodal Fact-Checking by Asking Relevant Questions?" (arXiv:2410.04616v2, 2025) — LLM-generated visual/textual probes enhance evidence retrieval and fact-checking robustness.
Source: arXiv:2410.04616
Grace
"Visual thinking" scaffolds (e.g., diagrams as prompts or in RAG) act as bridges to verbal chains, making reasoning more robust/compositional — seen in gains on visual QA, fact-probing, and retrieval where pure text falls short.
Visual Knowledge Graphs Improve Relational Interpretation
In knowledge-graph-like or structured-retrieval contexts, visuals unlock better interpretation of relationships, reducing reliance on purely textual embeddings.
Iron
"Pythia-RAG: Retrieval-augmented generation over a unified multimodal knowledge graph for enhanced QA" (Knowledge-Based Systems, 2025) — Builds unified MMKG (text + visual triplets + ConceptNet), fuses embeddings via self-attention; improves QA and cross-modal relationship interpretation over text-heavy baselines.
Source: Knowledge-Based Systems, 2025
VisGraphRAG-style multimodal KG RAG (various 2025 papers/examples) — Achieves higher accuracy (0.7629 vs. baselines 0.5805–0.6743), faithfulness, and cross-modal relevance via structural linking of images/questions/answers.
Source: Various 2025 multimodal KG-enhanced RAG studies
"Comparison of Text-Based and Image-Based Retrieval in Multimodal Retrieval Augmented Generation Large Language Model Systems" (arXiv:2511.16654v2, Nov 2025) — Direct multimodal embeddings significantly outperform LLM-summary-based approaches (13% absolute mAP@5 gain, 11% nDCG@5); preserves visual context vs. info loss in summarization.
Source: arXiv:2511.16654
Grace
Visuals in KG-like structures provide explicit relational cues (e.g., diagram nodes/edges), enabling better interpretation than text embeddings alone, especially for compositional or cross-modal tasks.
Iron: Directly sourced from peer-reviewed or preprint research with specific citations.
Grace: Logical extensions grounded in the cited Iron but not independently verified as standalone claims.
Noise: None included. All content is Iron or Grace, per SoulShine Logic protocol.
Happy innovating!
